What I mean by risk

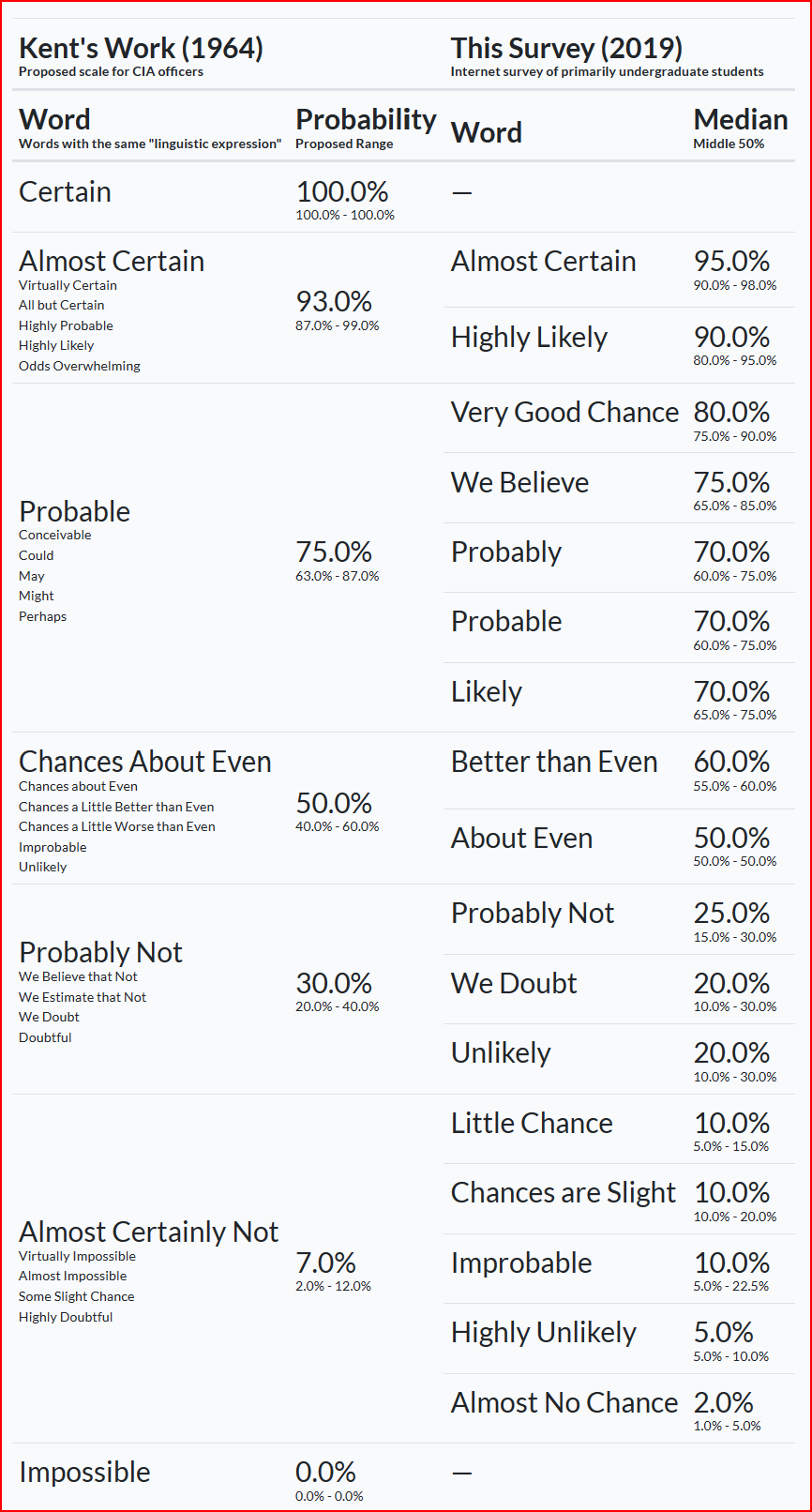
There is a very large risk management industry, much of it is useful but which parts are useful isn't so clear. When it came time to pick a speciality in risk management (2012), I chose likelihoods and assessing uncertainties. Likelihoods were good because they had to sum to 100%: no matter how many meetings it took to decide, at some point someone had to stare down a probabilistic chart like the one below and pick a number.
Early on I realised few people had been shown how to estimate, which meant that most estimations needed some ground truth testing. That led to a lengthy lab exercise detailed partly in previous posts where I looked at the decision behaviour of groups and which ones were better at assessing the likelihoods of unknown events.
I found a strong tendency for people to stick to inductive thinking (reasoning from generalisations), some appetite for deductive thinking practices (testing predictions from generalisations) but no appetite for abductive thinking (identifying likely explanations for incomplete observations).
Different groups would introduce variations to Sherman Kents scale, usually without understanding how it was built (via necessity of wartime intelligence communications) or what it was meant to do (use spoken language structures to orient people to better address underlying probabilities).
It all concerned me enough I put a lot of time learning how to estimate uncertainty via a community supporting independent brier score testing. A brier score is a way to verify the accuracy of a probability forecast. Someone well practiced in estimating uncertainty will have a low brier score; my target was 0.2 and I'm under that at the time of writing.
At around this time the big data era merged into the AI era. We had Cambridge Analytica which led to a large amount of regulatory change; there was the GDPR family of legislation; the big companies continued concentrating market power; quantum computers became a thing; and finally large language models are now eating the world.
The interesting thing about the mindboggling colossal size of the datasphere we've built up over the last 15 years or so is that it still, always, has to come down to someone making a probabilistic estimation. And that still has to sum to 100%. This simple law is, I believe, a flip switch which humans can access once we stop trying to explain the whole system and focus instead on observing the system at hand.
That system is a steady state of probabilistic interactions, made up of matter and which throws off data if someone is around to catch it. This goes to the important notion of risk as explained by Sam Savage in his book The Flaw of Averages:
If a tree with a coin sitting on a branch falls in the forest and no one is there to bet on the outcome, is there still risk? No. There is uncertainty as to whether the coin ends up heads or tails, but because no one knows or cares, there is no risk.
This helps identify there is an observable local difference between risk and uncertainty, which is an important distinction. The reason why it needs to be observable is to meet the test Carl Sagan laid down in the Demon Haunted World: if our argument rests on an invisible, incorporeal, flying dragon that only a special expert can see then we may well be dealing with weak evidence at best and fakery at worst. It needs to be a local difference because one of the basic elements of data is observability, which Luciano Floridi identified as data de signo, a difference between signs.
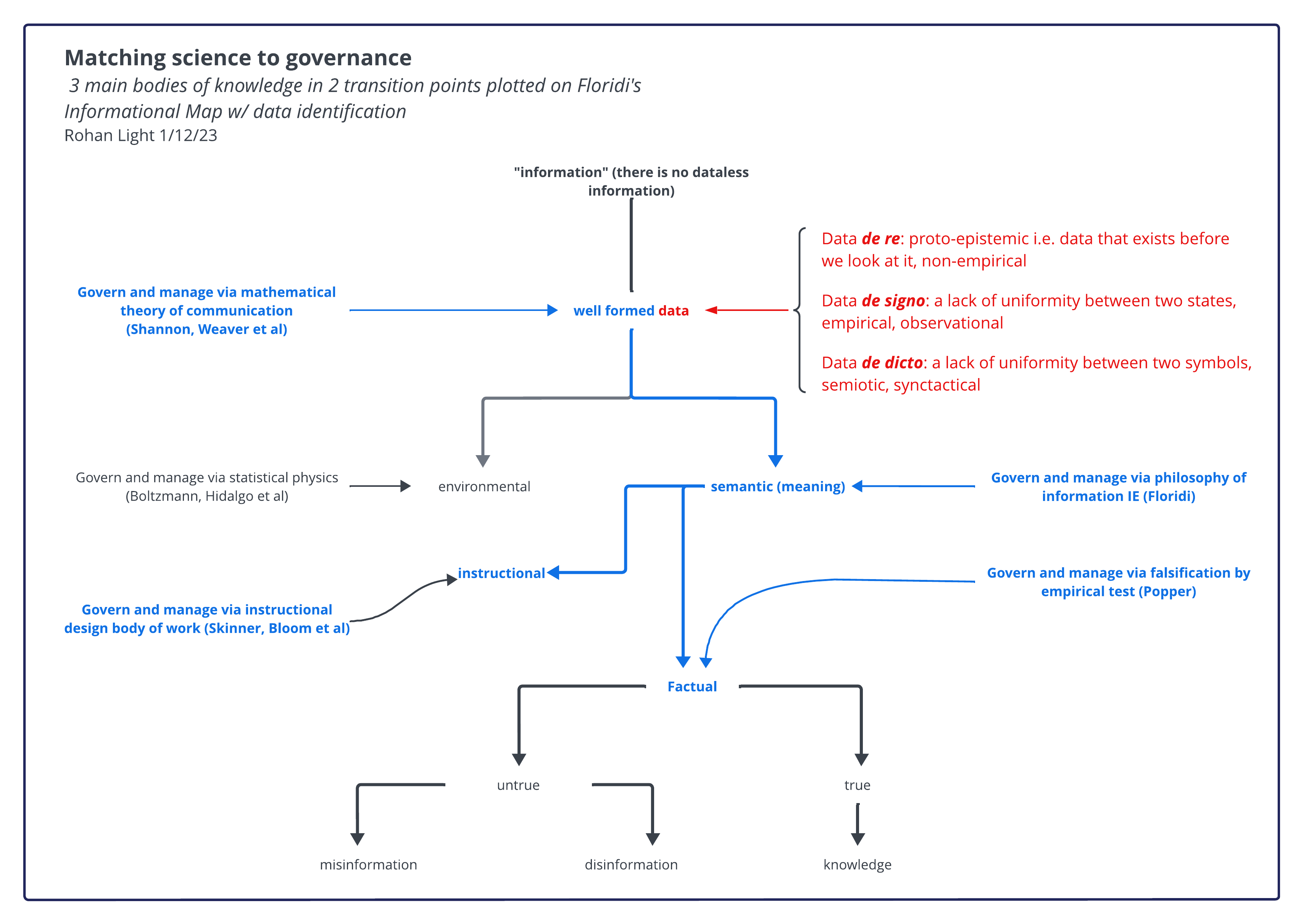
This is how the worlds of risk and data meet and match almost perfectly: they diverge later but at the point empirical observation (i.e. science) begins the underlying probabilities collapse into an observed state and voila! there is data. It is therefore a simple precaution in both the risk management and data governance fields to pay attention to the situation just prior to the observation. This leads later to causal diagramming; for the moment we're staying with this notion that data is best understood using probabilistic methods.
I've already covered likelihoods above: that just leaves randomness. Before speaking to randomness though it pays to restate decision risk: risk is the chance and cost of being wrong, where wrong is an obtainable course of action that I would have taken if I could have. The back end of that sentence is critical to enable counterfactual techniques, which leads to the causal diagramming. What we're looking at here in risk management terms is a latent visual description of uncertainty. Which is a fairly big deal in the trade but to get there takes more than a few steps.
The reason we focus on alternatives and options is their absence clearly identifies a lack of agency and where there is no agency then discussions about what the individual in question should do becomes empty. This goes to why good risk management focuses on innovation: we are interested in ensuring human agency within machine systems, the great problem of our age. Things haven't changed much in that regard since my 12-year-old third great-grandfather only escaped the workhouse by joining the army.
Randomness fluctuates depending on location, events and activities. A forest with no humans chopping it up has more activity-based background randomness. A crowd that is (Glastonbury) is different from a crowd that is (Hajj) or (riot on government buildings). Background randomness in (zen garden) is different from background randomness (rugby field). This is sometimes modelled as aleatory risk, which surely is using one more obscure word to better define another obscure word. I just call it background randomness or location risk. The below figure is how I approach a risk management problem, which is also quite handy for data governance problems.
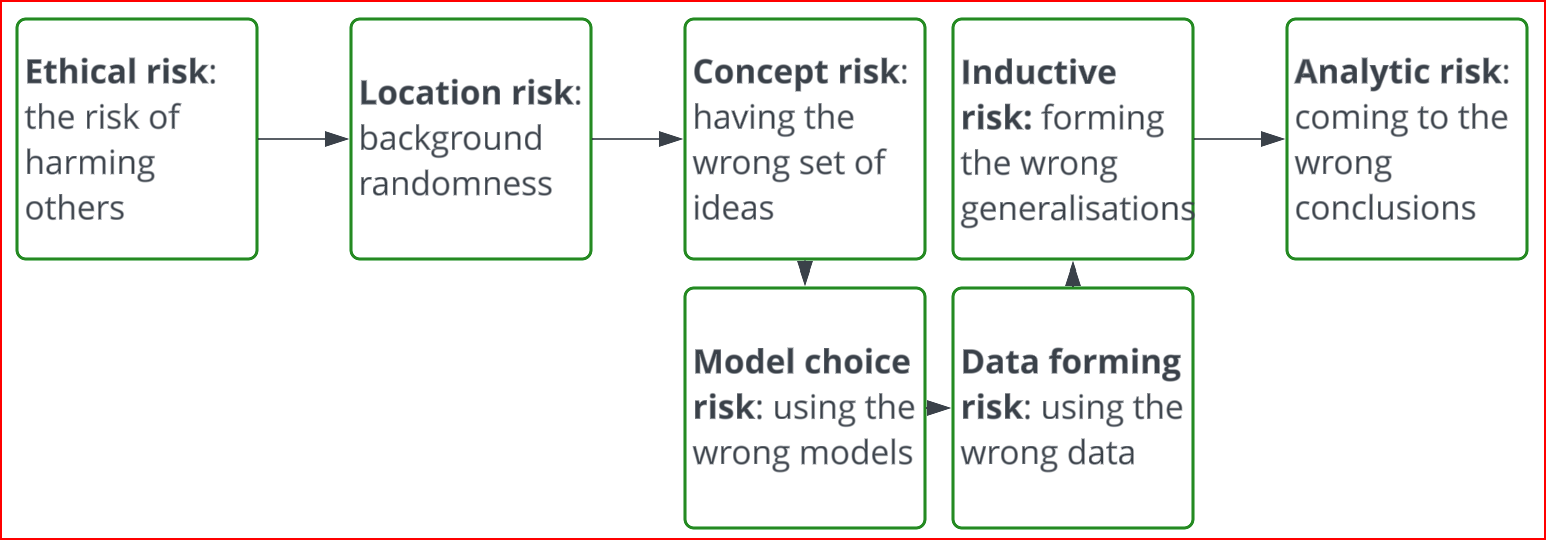
Working generally in risk management since 2012 and then into data governance, I've found this general formulation frames the underlying uncertainty, identifies the randomness, makes risk vectors easier to identify and, finally, means we'll genuinely be able to say that a particular risk event really does have only 38-42% likelihood of occurring. I'm covering this and more fun stuff in a book, of which this post is a part. P.S. thank you for reading this far.