The second risk of risk management

The first risk of risk management is faulty risk management models. The second risk is making a fundamental category error about what sort of causal risk we're facing. We can do well on the first, but can still crash and burn with the second.
The health system paradigm in Aotearoa New Zealand is getting a long overdue evolution, which hopefully ends up with a better performing entity in the lives of all kiwis. One of the paradigm shifts is an attempt to get in line with the times and realign the relationship with health service provider and health service consumer - on a community level.
Not so easy as it sounds as it necessitates a reckoning about the current state outcomes of 182 years of out-of-equilibrium power dynamics between the indigenous and colonising peoples. Plus making room for the 211 other cultures that call Aotearoa New Zealand home. And that's not counting our Muslim sisters and brothers, whose place here was so violently revealed by a hate filled terrorist.
I've been working with one of the brave souls tackling a rebalancing of funder, provider and consumer. Since 2020 or so I've been working with Dr Enrico Panai on issues of data and AI ethics. We use Luciano Floridi's family of models and my job is to design experiments and tests that make visible what is hard to see. I've been using health to test the usefulness of what we come up with and feedback to our core models.
Anyway, here's how I helped my client manage the second risk of risk management.
I work in causal risk models: they use the language of causal science to model prospective risk, without losing sight of innovation opportunities. They encourage matakite, foresight and situational awareness for the purposes of risk avoidance and benefit realisation. (You may think model elements that explain themselves such as 'to see into the future, prophesy, prophesies, foresee, foretell' as somehow different from all model elements that fail the first risk of risk management or the vast $$$ we drop into marginally performing prediction engines. I can confirm that better use of complementary languages opens up options we never thought existed).
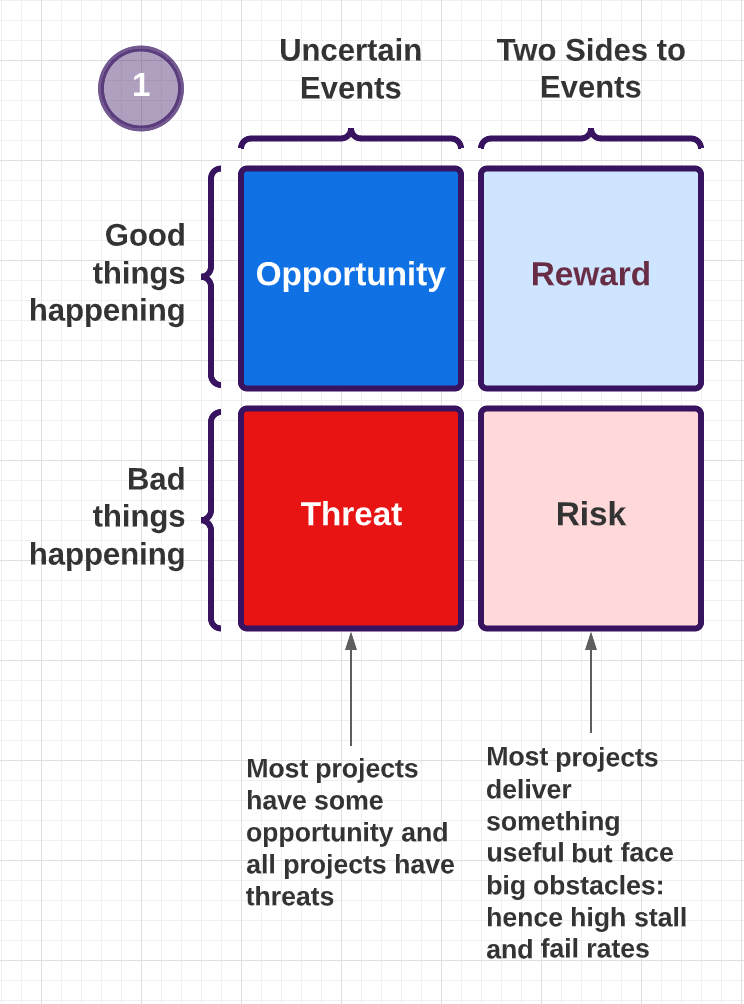
There are two sides to uncertainty (and two sides to each of those two sides). Some of these effects are helpful (opportunities), while others are not (threats) We manage opportunities as innovation and the threats as risk, all the time not fully understanding how the two relate.
Basically, we have to preserve all the good paths within the opportunity as well as managing risk. But if we approach it wrong, we'll manage the risk by stopping the opportunity. I work in change and risk, so I'm very keen on keeping those opportunity potential outcomes in play.
Here's the base causal model. The taijitu represents the good and bad potentials, how they mix together in a constant fluid future state. I keep it there as a constant: it's a way of making the unknown at least visible, giving us a chance to get out of our Dunning-Kruger state.
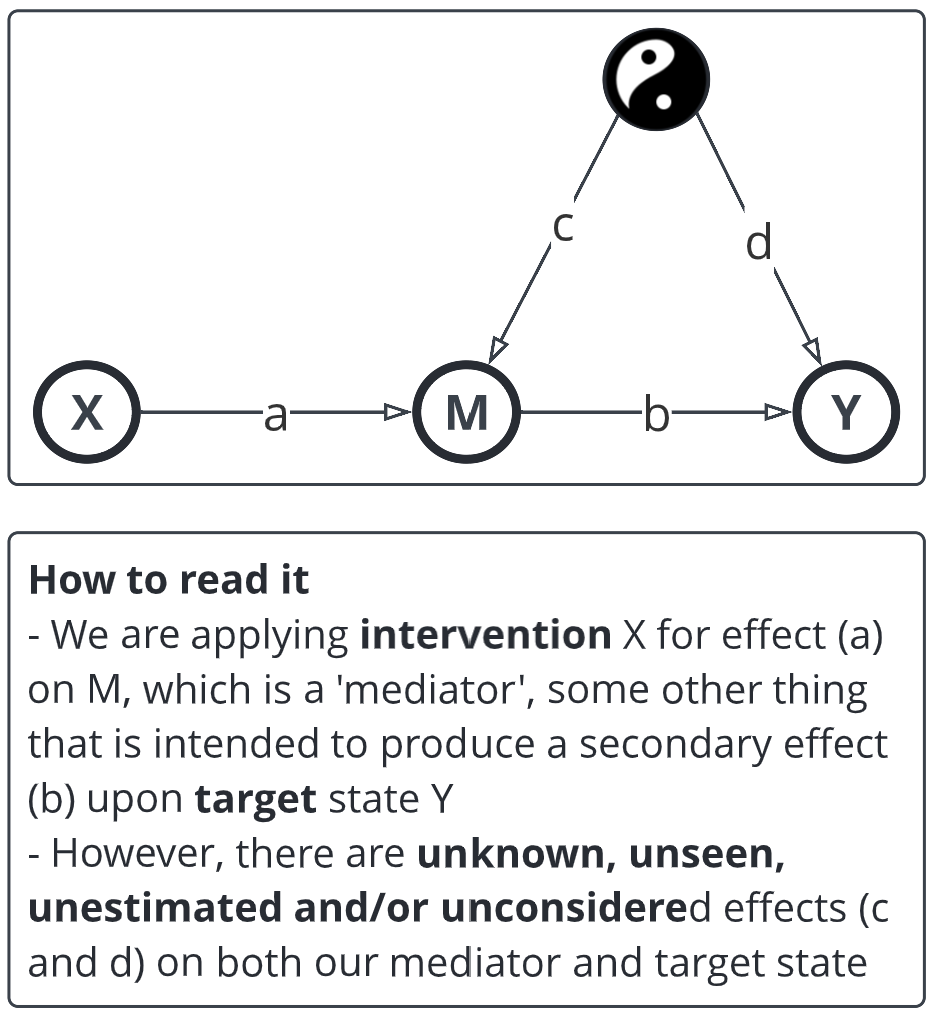
I render a lot of my work in comic form: it's such a successful communication form since the Middle Ages, I don't get why we downgrade the form. Anyway, the wordy bits explain the model. After a while your eye and brain will start doing additional work in the back of your head and, after an initial wtf, the comprehension point is soon reached.

Ok, so now I'm starting to point the model towards that chaotic set of future potentials, some of which we want and others we don't.
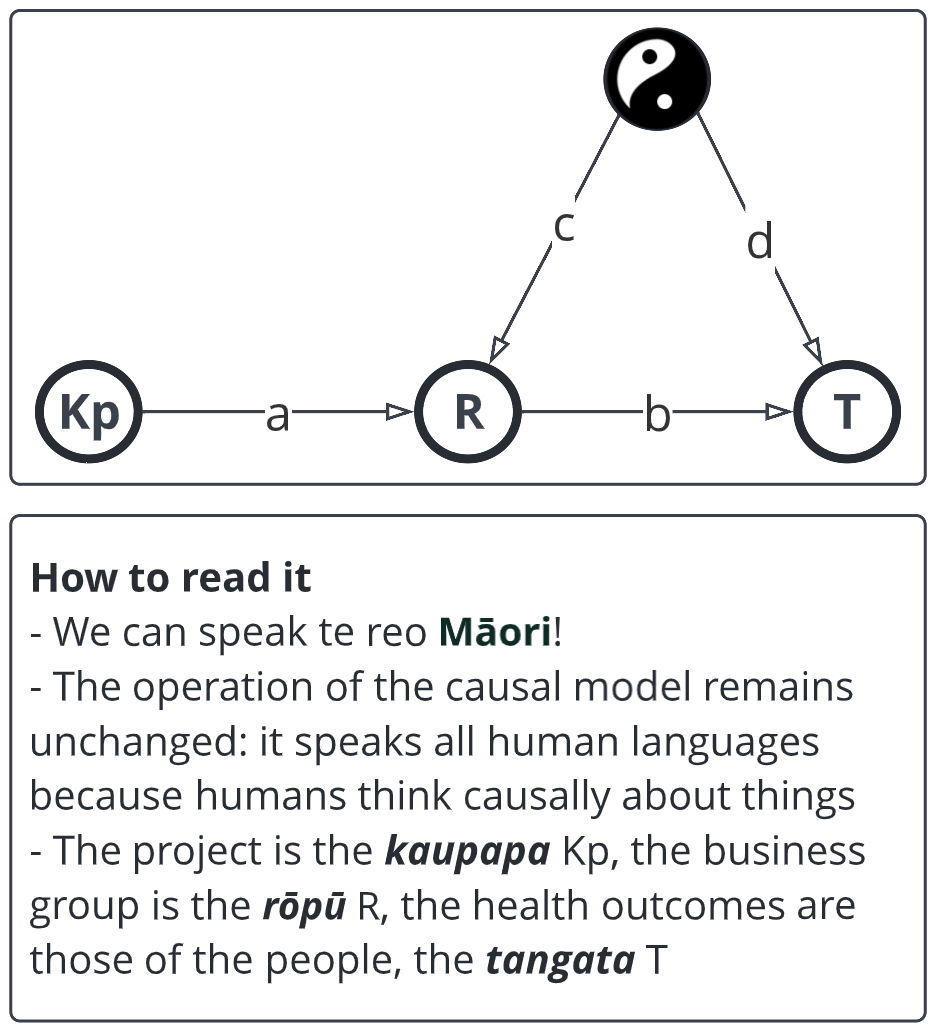
Some things (like 'privacy') need help when crossing cultural boundaries. But if you have a human brain then you can learn to read a model expressed as a causal diagram. Some terms mean much the same across cultures and once we get used to interchangeable terms, we can use causal models as a sort of Rosetta Stone.
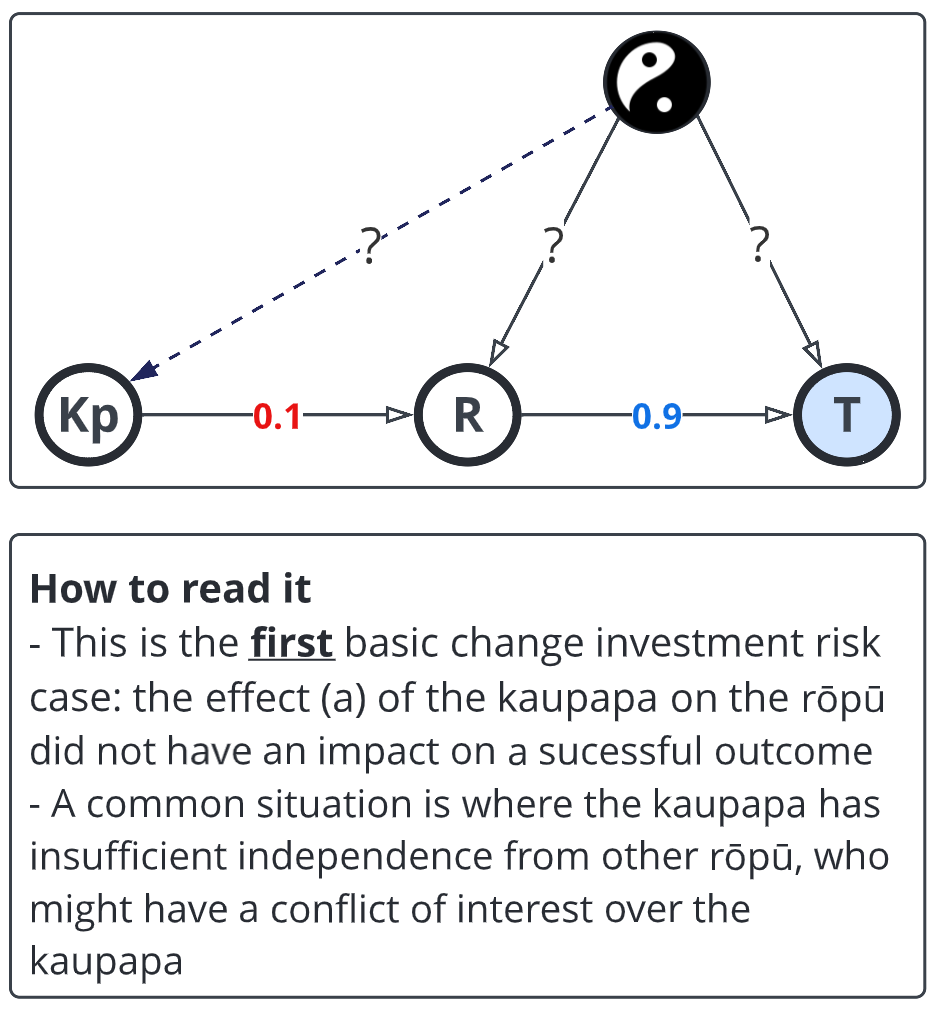
Now we use the model to identify different potential states. It's just a case of playing with the path co-efficients (DO NOT view them as correlations - they describe causal influence). I've dropped a dotted line from the unknown to the kaupapa on this one to show that the project is getting a potentially full blast of bad from something (often a rival group in health shhh).
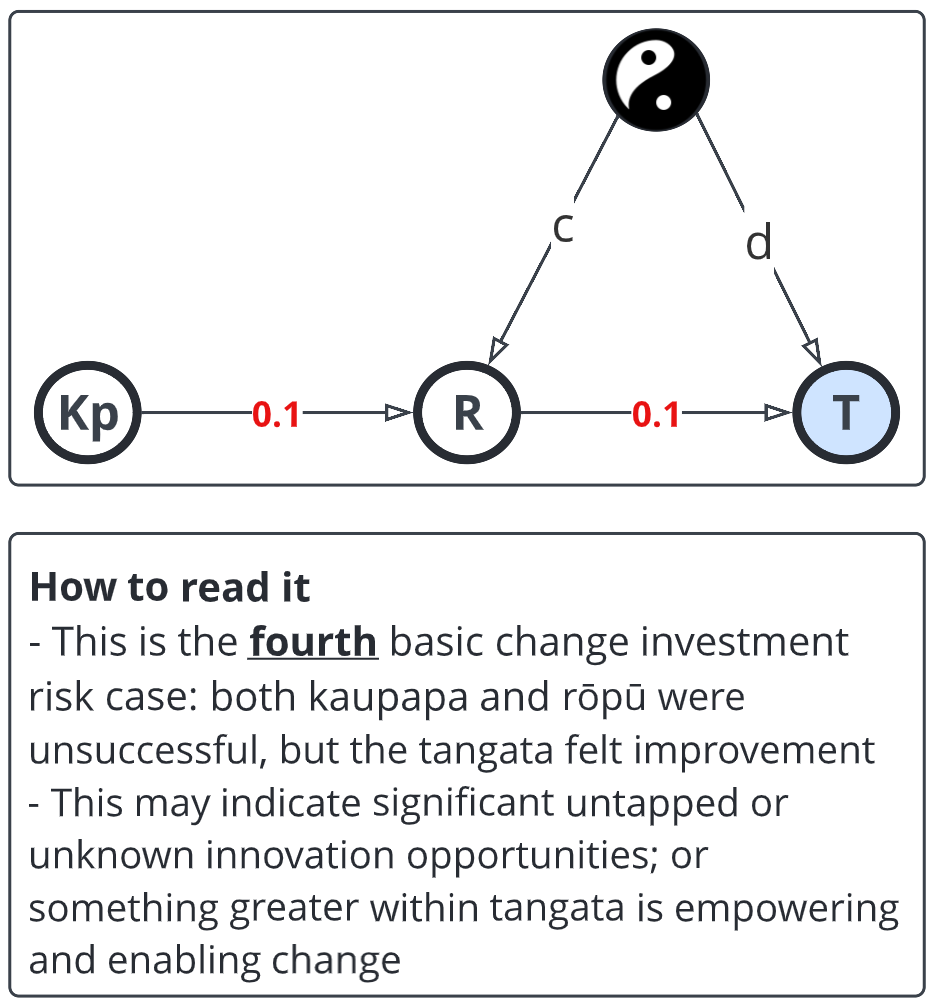
This is somewhat depressing: the project didn't do well, but the business unit just didn't make much impact and the people are worse off.
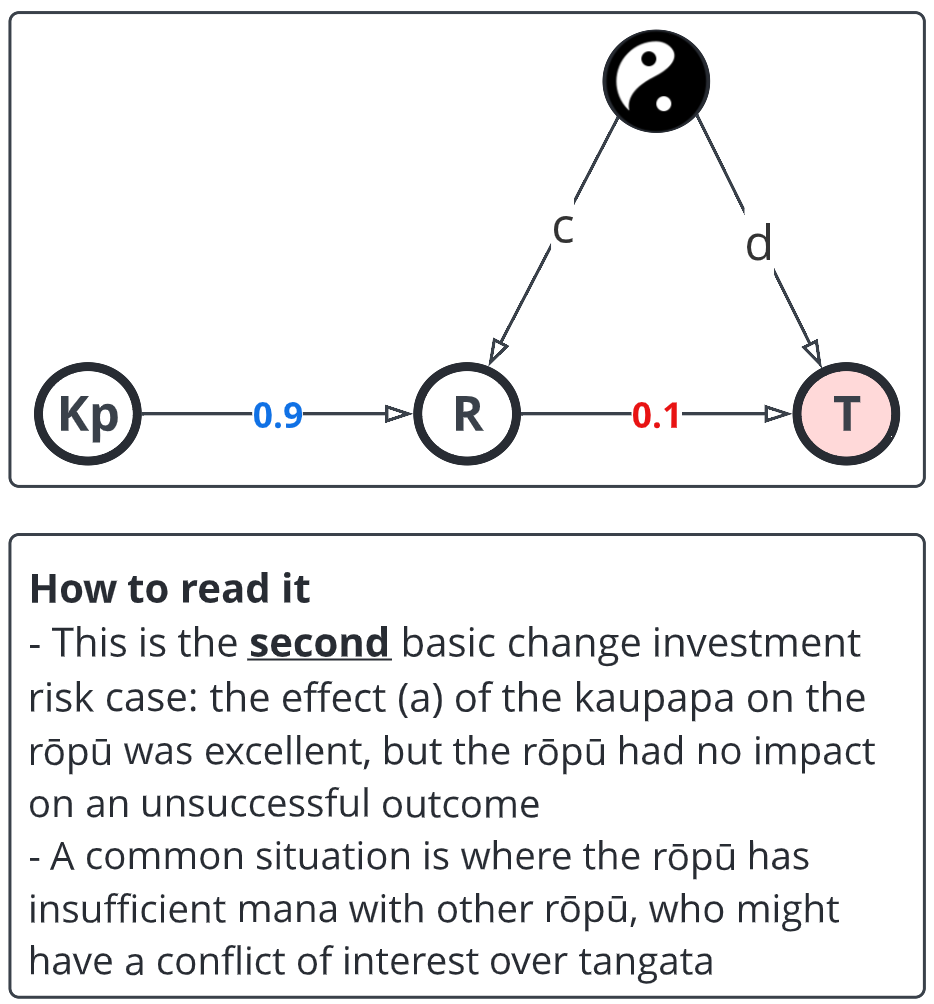
This is more depressing: the health system works perfectly, but te tangata are still losing.
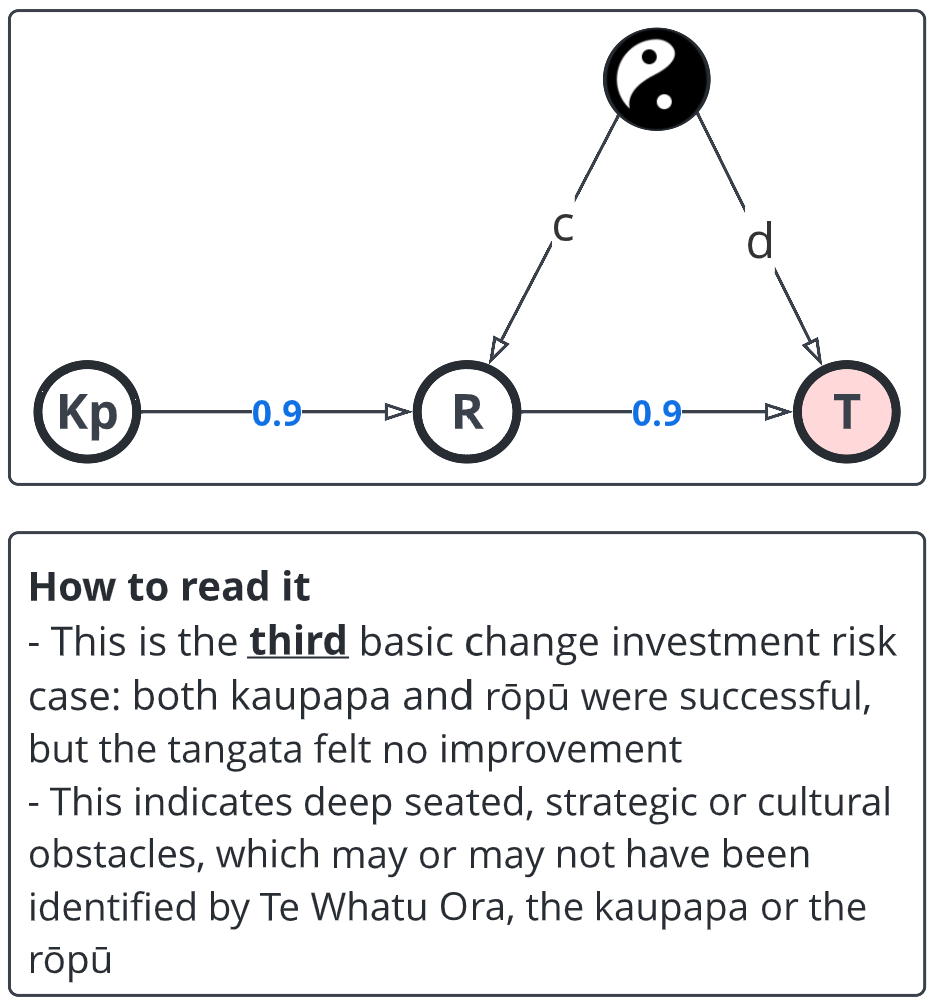
This is the one that's in the back of many people's minds: to what extent does the system working well make everything worse.
I'm just sticking to four at the moment. We can often get close to eliminating 80% of uncertainty with a few tests of simple models. We'll get into the next level soon - both at the empirical level here on the ground and also at the theoretic level with a paper published on Digital Society.
The main point of this post is we have to work to make the invisible observable - but once we solve the first risk, it's easier than you think.