The AI Knowledge Payoff: Why Our Baseline Truth Matters Most
We tend to think the value of AI is about model quality. In practice, the payoff we get from AI depends just as much on our own knowledge and how accurately we judge what we know.
We can think of this as an AI Knowledge Payoff (AIKP): how much useful work we get out of an AI system once we mix human expertise, machine calibration and human bias.
Here’s a simple way to turn that into algebra—and why it matters for how we deploy AI.
1. Three inputs that drive AI payoff
To make this work, we put everything on a 0–1 scale, like probabilities or utilities.
V – Verified Prior Knowledge
How much true domain knowledge we actually have.
Scale: 0 = total ignorance, 1 = deep, reliable expertise.
C – AI Calibration Score
How reliable the model is. Think of this as like a Brier Score with a 0–1 scale, where 0 is untrustworthy and 1 is very well‑calibrated.
Kp – Perceived Knowledge
How much we think we know.
Scale: 0–1, independent of reality.
Intuitively:
- Higher V and C should increase payoff.
- A big gap between Kp and V (overconfidence or underconfidence) should reduce payoff.
2. Capturing Dunning–Kruger and impostor syndrome
To model bias, we introduce a penalty term that grows as perception drifts away from reality.
Let: D=1+α⋅∣Kp−V∣
- D is the bias penalty.
- α≥0 controls how strongly miscalibration hurts us (e.g. α=1 for illustration).
- If Kp=V: no penalty, D=1
- If Kp is far from V (too high or too low): D increases.
This gives:
- Dunning–Kruger (low V, high Kp): big |Kp − V|, big D, low payoff.
- Impostor syndrome (high V, low Kp): also big |Kp − V|, lower payoff because we under‑use the tool or over‑verify everything.
We don’t let the maths blow up when V = 0; we just treat low‑V users as low‑V.
3. The AI Knowledge Payoff equation
Put it together: AIKP=V⋅C/D
Where:
- V⋅C is the potential payoff from combining human expertise with a calibrated model.
- D reduces that payoff when our self‑assessment is badly off.
What this implies
- If we raise C (buy a better model) but V is low and |Kp − V| is large, AIKP stays low.
- If we raise V (train people) and align Kp with V, AIKP climbs quickly—even with the same model.
- If C is poor, even perfect human calibration can’t rescue the payoff.
4. Some scenarios
Assume α=1 to keep it simple.
Scenario A: The calibrated expert
- Profile: High actual knowledge, accurate self‑assessment, good AI.
- Inputs: V=0.9, Kp=0.9, C=0.9
- Penalty: D=1+∣0.9−0.9∣=1
- Payoff: AIKP=0.9×0.9/1=0.81
Interpretation:
This is where AI shines. Strong expertise, honest self‑assessment, solid model. The human-artificial knowledge agent system is doing real work.
Scenario B: Classic Dunning–Kruger
- Profile: Low actual knowledge, high confidence, same good AI.
- Inputs: V=0.2, Kp=0.8, C=0.9.
- Penalty: |Kp − V|=0.6, so D=1.6
- Payoff: AIKP=0.2×0.9/1.6≈0.11.
Interpretation:
The model is good, but the user doesn’t know what they don’t know. They over‑trust outputs, under‑verify and their net value from AI is almost negligible.
Scenario C: Impostor syndrome
- Profile: True expert, but underconfident, good AI.
- Inputs: V=0.9, Kp=0.4, C=0.9.
- Penalty: |Kp − V|=0.5, so D=1.5.
- Payoff: AIKP=0.9×0.9/1.5=0.54.
Interpretation:
They’re good and the model is good, but they second‑guess, over‑verify and under‑use the system. Payoff is decent but far from the 0.81 they could get.
Scenario D: Unhinged AI
- Profile: Real expert, accurate self‑view, badly calibrated model.
- Inputs: V=0.9, Kp=0.9, C=0.2.
- Penalty: D=1
- Payoff: AIKP=0.9×0.2=0.18.
Interpretation:
No amount of human wisdom can turn a fundamentally unreliable model into a high‑payoff system.
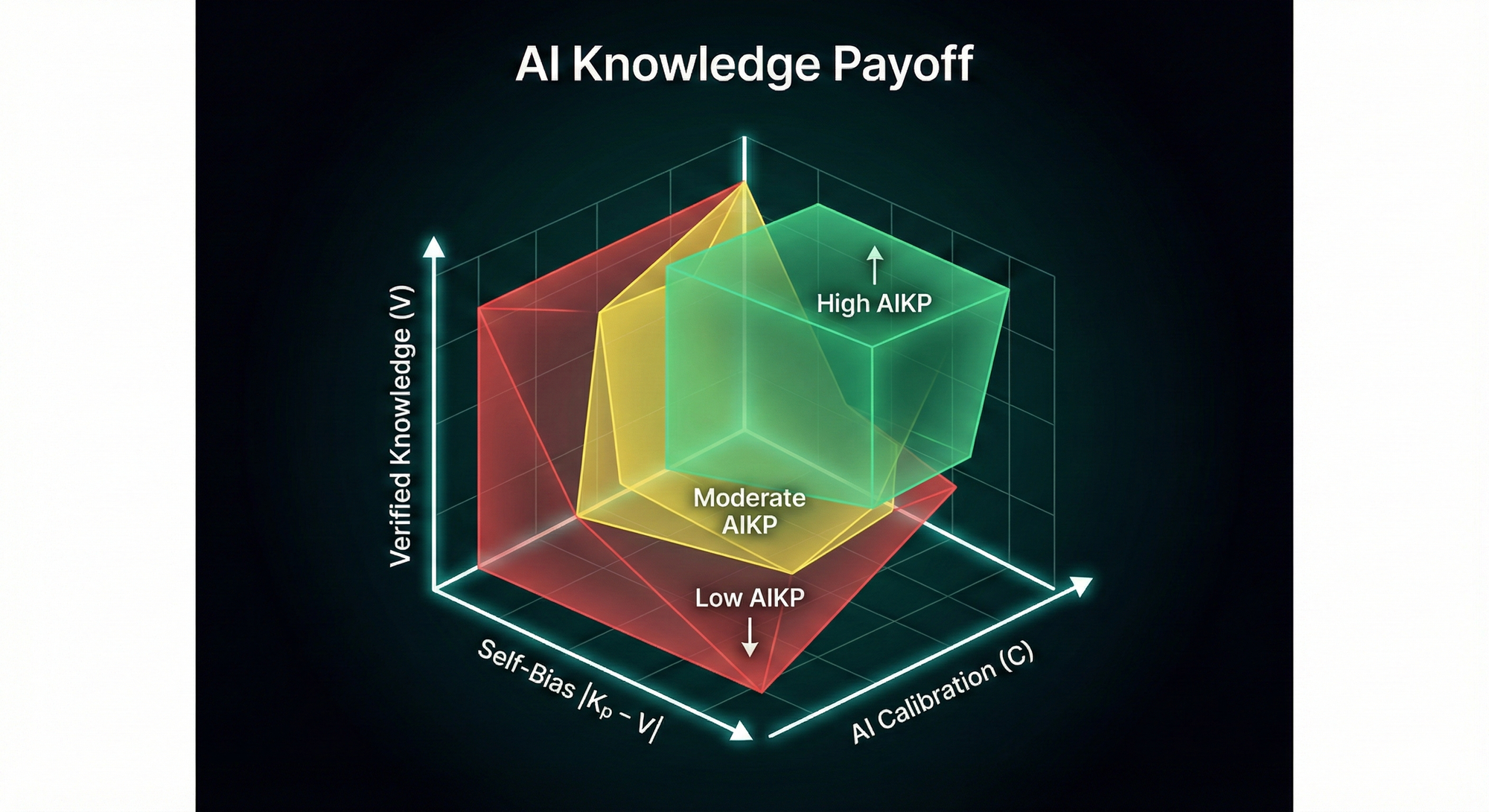
5. A simple 3‑axis visual
We can picture this as a 3‑axis chart:
- One axis: V (verified knowledge).
- Second axis: C (calibration).
- Third axis: |Kp − V| (miscalibration of self‑belief).
High AIKP lives where:
- V is high.
- C is high.
- |Kp − V| is low.
6. What this means for AI strategy
This simple equation backs up a critical point:
- Buying better models (raising C) is not enough.
- We also need to:
- Raise V: invest in domain expertise and data literacy.
- Reduce |Kp − V|: help people calibrate their confidence to reality (training, feedback, UX that surfaces uncertainty).
If we only spend on tooling, our AI Knowledge Payoff will plateau.
If we invest in people, calibration and metacognition together, we move into the green zone where AI genuinely multiplies human capability.